Workflow-based data analysis with KNIME
Visualization: Histogram
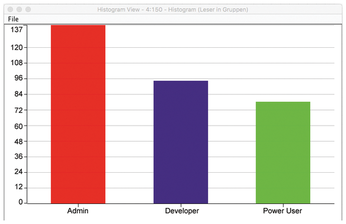
A histogram, provided by the histogram node, provides an overview of how many readers lie in which group. The histogram node can be connected directly to the Cell Replacer from the previous step, but the whole thing looks a bit colorless. The Color Manager node lets you assign a color – based on the value of a column – to the rows of a table. If the same column is also used for the x-axis of the histogram, KNIME automatically takes over the color for the bars (Figure 6).
Visualizing Multiple Dimensions
Visualizations are available to display data and also show whether the discovered clusters have any significance. In the past years, many visualization methods were implemented in KNIME with the help of JavaScript and the D3.js framework [2].
These visualizations are available in the KNIME Javascript Views extension, which is where you will also find the Parallel Coordinates visualization. Parallel Coordinates represents the properties of the data with parallel y-axes (Figure 7).
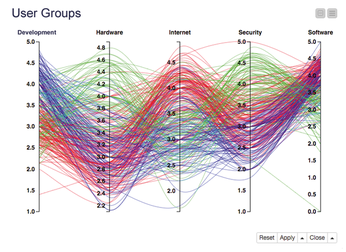
D3.js, the JavaScript library on which most KNIME JavaScript visualizations are based, is one of the most widely used libraries for creating interactive data visualizations in the browser. However, the KNIME user can only use some of its possibilities.
For all cases that KNIME does not yet cover, use the Generic Javascript View. Configuring this node means you can enter arbitrary JavaScript and CSS code to compute a colorful image from a table. The code executed by the node has access to the node table and the browser Document Object Model (DOM) and can generate HTML and SVG elements based on the data.
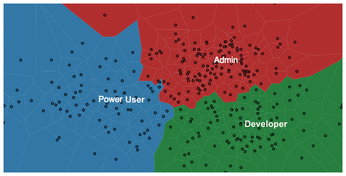
For example, you can use the Generic Javascript View to create a Voronoi diagram (Figure 8), which visualizes the clustered reader groups in 2D. To ensure that the data is in a format suitable for visualization, you must first reduce the number of dimensions. Up to now, the example has used five dimensions per reader (one for each section), but I will now break this down into two using the principal component analysis as calculated by the PCA (Principal Component Analysis) node. This type of transformation reduces the dimensionality, but at the same time tries to keep the variance in the data as complete as possible so that as little information as possible is lost.
By this point, a proper data analysis workflow has already been created: from importing the data, through transformation and grouping, to visualizing the results. All this helps to gain interesting insights into the raw data. In a further step, it is now possible to identify for each reader the articles that a reader has not yet read, but which could also be interesting for the reader because of their interests. A web application can then suggest these articles to the reader.
Keeping Track
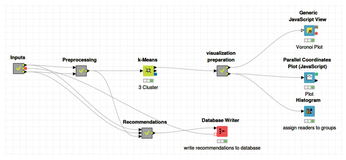
With each further step, the workflow threatens to become more complex and confusing. To ensure that it remains comprehensible, it is a good idea to encapsulate individual parts in modules to conceal the complexity. This encapsulation is made possible using so-called meta nodes. Meta nodes also let you group the sections of the workflow using meaningful names. Figure 9 shows a possible restructuring of the workflow using meta nodes.
« Previous 1 2 3 4 Next »
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs