Elasticsearch, Logstash, and Kibana – The ELK stack
Logstash
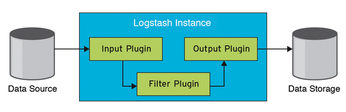
Logstash [2] processes and normalizes logfiles. The application retrieves its information from various data sources, which you need to define as input modules. Sources can be, for example, data streams from Syslog or protocol files. In the second step, filter plugins process the data based on user specifications; you can also make this phase simply forward the material without any processing. The output modules finally output the results; in our lab, everything goes to the Elasticsearch service. Figure 2 shows how the components interact.
Like Elasticsearch, Logstash is free and available under the Apache license. The project page offers the source code, Debian and RPM packages, and notes about the online repository.
We installed version 2.1.0 from November 25, 2015. Logstash also needs a Java Runtime Environment. It does not include a systemd service unit; instead, the vendor provides a legacy init script – unfortunately, without a reload parameter – because Logstash is not currently capable of dynamically reloading its configuration. A bug report had already been submitted when this issue went to press.
Building Blocks
You can configure Logstash in the /etc/logstash/conf.d directory, which is empty by default. The vendor does not deliver a simple default configuration and thus does not give users some quick guidance on how to achieve some initial results and understand the interaction of the Logstash pipeline. That said, the reference [8] is a good place to look for exhaustive explanations about all the plugins, and searching the web reveals numerous examples by other users that you could use as a template.
Because Logstash parses all the setup files from /etc/logstash/conf.d in alphanumeric order and connects them to create an overall configuration, it is a good idea to think about the structure up front. The test computer uses the following schema: The input files start with a , the filters with 5, and the output modules with 9. The filenames are preceded by a four-digit number, leaving plenty of scope for experiment.
The simplest example is 0005-file-input.conf (Listing 2), which reads local logfiles. It uses the file input module and defines as the sources the Nginx access logfiles from the local machine (line 12); exclude rules out files with the .gz suffix, and type is an optional descriptor that the filter plugins can reference (see the "Extracted" section).
Listing 2
0005-file-input.conf
If you want to collect and process logs from remote servers in addition to local logs, you can draw on Syslog itself for some help (Listings 3 and 4 and online [6]). The Logstash forwarder and Filebeat offer you an alternative (see the "Woodcutters" box).
Listing 3
0001-syslog-input.conf
Listing 4
0002-socketsyslog-input.conf
Woodcutter
The Logstash server can receive data from remote computers. Earlier versions relied on a Logstash forwarder [9] to do this. A small tool that ran on each server collected the logs locally and then sent them to the central Logstash server using the Lumberjack protocol. The 0201-lumberjack-input.conf file (Listing 5) shows an example that makes the Logstash server available for existing legacy installations using Logstash forwarders.
In Logstash 2, the developers introduced Filebeat [4], a universal service that relies on the Beats protocol [10] to send data streams to a specific port on the Logstash server. Filebeat will replace Lumberjack in the long term. The Beats protocol, which has only been around since Logstash 2, is also used for other data shippers. We installed Filebeat version 1.0.0 dated November 24, 2015, from the project website. The /etc/filebeat/filebeat.yml contains meaningful defaults, which you can easily modified to suit your needs. The example file [6] shows the setup for the test machine.
One of Filebeat's advantages is that the tool can use SSL to send the collected logs on request to the Logstash server. Additionally, administrators can equip the Filebeat clients with certificates themselves and thus define the computers from which they receive logs. Another benefit is the registry file, which Filebeat users to remember which files it has already read and sent. In other words, if the Logstash server is not available, Filebeat can restart at a later time from where the transmission was interrupted.
Filebeat can theoretically deliver directly to Elasticsearch, and this is the default setting in the configuration (Output section). Because this does not include processing with filters, but simply sends the data streams to the index as is, we commented out this option on our test machine. Instead, Filebeat sends its data to Logstash.
Listing 5
0201-lumberjack-input.conf
The filter modules process everything that has reached Logstash from the sources. They analyze the data streams and break them down into individual snippets of information and data fields. In addition to the modules for parsing and breaking down, other modules add more detail to enrich the raw data, including, for example, dns (DNS name resolution) and geoip (IP geolocation from the MaxMind database).
Extracted
All Logstash plugins, including the filters, are Ruby Gems. You can use the /opt/logstash/bin/plugin scripts to manage these extensions on your own system [11], list existing modules (Figure 3), install new ones from the web or from your local disk, and update existing modules. In addition to the included filters, you have access to a number of community plugins not written or updated by Elastic.

To define which filters are allowed to access what data, you can use if … else statements that use standard fields, such as the previously mentioned type descriptor set by many input modules. Tags, which Filebeat can define, can serve as differentiating criteria for filters. Basically, all of the fields discovered in the upstream process are available, including fields that have just been extracted from a line in a logfile.
The 5003-postfix-filter.conf file [6] provides an example:
[...]
if [postfix_keyvalue_data] {
kv {
source => "postfix_keyvalue_data"
trim => "<>,"
prefix => "postfix_"
remove_field => [ "postfix_keyvalue_data" ]
}
[...]In this case, the kv filter (extraction of key-value pairs) is only used if the postfix_keyvalue_data field is defined.
The frequently used grok module can parse certain log formats, breaking down the body text into individual data fields, orienting its work on popular regular expressions, and supporting references to previously defined templates. Logstash itself contains a number of Grok patterns in the logstash-patterns-core plugin.
Developing your own patterns is not a trivial task. You will find a number of half-baked attempts on the web, but also some good examples under free licenses that you can add to your own configuration. You will find a very good pattern for Postfix [12], examples for Dovecot [13], and Nginx patterns [14]. The GitHub repository [15] collects templates for services such as Bacula, Nagios, PostgreSQL, and more.
The trial and error method of creating meaningful Grok patterns – requiring continuous Logstash restarts – is not a good idea and takes far too long. Two online tools solve this problem. Administrators can develop and test their Grok patterns on two sites [16] [17] before adding them to their Logstash configurations and restarting the service. You will also want to keep an eye on the configtest parameter of your Logstash init scripts and check your setup files for syntax errors using the /etc/init.d/logstash configtest command.
« Previous 1 2 3 4 Next »
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs