Get hiking suggestions from your recorded tours
Programming Snapshot – Go Filters
When Mike Schilli is faced with the task of choosing a hiking tour from his collection of city trails, he turns to a DIY program trained to make useful suggestions.

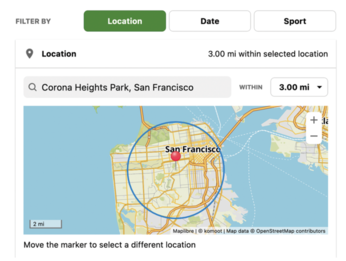
Which of the city walking routes recorded on the Komoot route planning service should I do again today? This is a question I ask myself surprisingly often. Depending on how I feel, I want the day's tour to be short or long, hilly or flat, and – accordingly – challenging or relaxing. Depending on time constraints, I might not want to venture too far from home.
My tours are recorded on the Komoot service, but it offers only very rudimentary filter options (Figure 1). In my case, using its smallest possible search radius of three miles, Komoot searches the entire San Francisco metropolitan area for saved tours rather than letting me narrow my search to individual neighborhoods. To enable more granular search criteria, what I have in mind for today's column is a command-line tool that uses the elevation profile, tour time, and distance to trail entry as filters to greatly reduce the selection.
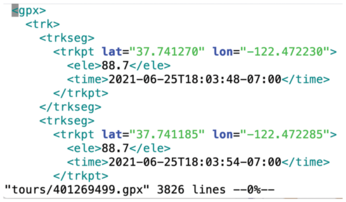
The new tool can make its selection from tour data that is already available as GPX files on my hard disk from a previous Snapshot column [1]. This XML format records the waypoints of the respective tour as geo-coordinates with elevation above sea level, including timestamps (Figure 2). In the absence of a publicly available API on Komoot's website, a web scraper in the previous column logged in to the site, fetched the GPX data, and copied it locally to the tours/ directory on the hard disk using the numeric tour ID as a filename (as in 523799045.gpx).
For post-processing, the CSV file in Listing 1 assigns easily recognizable route names to those IDs. What you see here is a selection of my tours, some of which are located in Germany and some in the USA. The rest of the conversion flow is now automatic. A preprocessor wades its way through the GPX data of all tours, determines their total duration, the elevation climbed, and the distance from home to the trailhead. Equipped with this metadata, a command-line program in Go later filters out the tours based on given criteria.
Listing 1
tour-names.csv
id,name 401269499,Forest Hill Parkside Farmers Market 411337149,Presidio 394385030,Vulcan Stairs and around Buena Vista 526430358,Aggenstein 434310884,Heidelberg Schlierbach 418406673,Tank Hill Mt Olympus 514603221,Bernal around the Hill 434601991,Heidelberg Philo-Altstadt-Schloss 510083576,Forest Hill Stairs Mini Loop 405638419,Around Mt Davidson 393675355,Laidley Glen Park Loop 416081317,Sanchez-Mission
Dizzying Heights
Among other things, how strenuous a tour is depends on the meters of altitude the hiker needs to walk uphill. Each waypoint in the GPX file (Figure 2) not only contains the geolocation's longitude and latitude (trkpt lat/lon), but also the current elevation above sea level in meters (ele). So, on a rising route, the height value will increase from point to point.
In order to compute the length of all uphill sections in meters above sea level for the tour, the algorithm needs to run through all the waypoints of the route, determine the difference in elevation to the following point by subtraction in each case, and finally add up these differences. Negative values are filtered out beforehand, because only the uphill gradients make the route more strenuous, not the downhill sections.
Listing 2 elegantly solves this task with just a few lines of R code. Installing R with your distribution's package manager, for example, on Ubuntu via
sudo apt-get install r-base-core
Listing 2
climb.r
01 #!/usr/bin/env Rscript
02 library("gpx")
03 hike <- read_gpx("tours/686129674.gpx")
04 track <- hike$tracks[[1]]
05 ele <- track$Elevation
06 steps <- diff(ele)
07 upsteps <- steps[steps > 0]
08 print(sum(upsteps))
gets you the interpreter pretty quickly, but it does not install the GPX library needed by the program. To install the GPX library on your local machine from the Comprehensive R Archive Network (CRAN), type
install.packages('gpx')in an interactive R session (just call R at the command line). After doing so, the search path contains the Rscript program, which the listings in this column call from their shebang lines at the start. Rscript runs the individual listing's code through the R interpreter, so you can simply call the program name from the command line (like ./climb.r in the case of Listing 2), after giving it executable permissions.
Let's look at the code: The read_gpx() function called in line 3 comes from the previously installed gpx library and expects the path to a GPX file. If the call is successful, the return value is a hodgepodge of named data containers and an array with tracks, which I cunningly named tracks. A GPX file can contain several of these, but only the first one is needed here. Line 4 retrieves the corresponding dataframe with the hike$tracks[[1]] expression (array element numbers in R start at one and not at zero) and assigns it to the track variable.
Figure 3 shows the data of the dataframe stored in the track variable. Because the elevation values in the track dataframe are in the Elevation column, line 5 extracts them with the expression track$Elevation. The script then assigns this vector with all the elevation values in the waypoints in the file to the ele variable.

Only Uphill Counts
Because the elevation values of the measuring points all lie in the ele vector, R's built-in diff() function determines the individual differences between them. The result is again a vector. If ele had the values (2,10,8,12), diff() would make (8,-2,4) out of this. The recode statement in line 7 filters out the negative values, leaving only (8,4) in the example. The sum() function in line 8, which is also from the standard R library, grabs this vector and adds up its individual elements. In the example, the result would be 12.
The script in Listing 2 can be called from the command line. It outputs the sum total of meters of altitude climbed during the tour as an integer to the standard output. However, the filter program shown later does not just need the meters of altitude for one tour in the collection, but the values of all tours. In addition, besides the altitude meters, it also requires the latitude and longitude of the track's starting point and the duration of the tour in minutes. The preprocessor shown in Listing 3 provides the metadata for all the tours and creates a CSV file following the example in Figure 4.
Listing 3
preproc.r
01 #!/usr/bin/env Rscript
02 library("gpx")
03 idnames <- read.csv("tour-names.csv")
04 for (row in 1:nrow(idnames)) {
05 id <- idnames[row, "id"]
06 gpxf <- paste("tours/", id, ".gpx", sep="")
07 hike <- read_gpx(gpxf)
08 track <- hike$tracks[[1]]
09 # elevation
10 ele <- track$Elevation
11 steps <- diff(ele)
12 upsteps <- steps[steps > 0]
13 idnames[row,3] = sum(upsteps)
14 names(idnames)[3] = "ele"
15 # starting point
16 idnames[row,4] = track[1, "Latitude"]
17 idnames[row,4] = track[1, "Latitude"]
18 names(idnames)[4] = "lat"
19 names(idnames)[5] = "lon"
20 # duration
21 start <- track[1, "Time"]
22 stop <- tail(track, 1)[1, "Time"]
23 mins <- round(as.numeric(difftime(stop, start), units="mins"), 0)
24 idnames[row,6] = mins
25 names(idnames)[6] = "mins"
26 }
27 write.csv(idnames)

How does the preprocessor work now? First, Listing 3 reads the CSV data from tour-names.csv (Listing 1) and fields a dataframe with the id and name columns. The for loop starting in line 4 iterates through all rows of this dataframe. Line 5 extracts the tour's numeric id, and line 6 compiles the path to the GPX file on disk from the id. The read_gpx() function then reads the tour data in GPX format from the downloaded file, and the remaining altitude calculation is analogous to Listing 2. Next, I need to append the computed numerical elevation change value to the dataframe in a new column named ele.
More Columns
To add a new column to a dataframe, you just need to assign a value to it. To do this, you can use either the dollar notation (idnames$newcol) or the index numbers for row and column as in idnames[row,col], where col is the new column number.
In the case at hand, row is the index number of the data series currently being processed by the for loop, and col is equal to 3, because we want "ele" to be the third column in the dataframe. Assigning the sum value to idnames[row,3] will append the new column, but to make sure that it is given a name and not just new values, I also need to modify the names(idnames) array in line 14 by appending an element with the new column name.
It is important to insert a new column value before assigning a name to it, though, so that R knows that the dataframe has grown. After doing this, and only then, the name can be stored in names. Any attempt to do this beforehand throws an error message because R thinks that the dataframe is not big enough.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia