Smart research using Elasticsearch
More, Please

Websites often offer readers links to articles about similar topics. Using Elasticsearch, the free search engine, is one way to find related documents instantly and automatically.
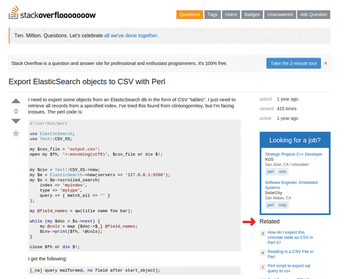
When people rummage around on the StackOverflow website looking for advice on programming questions, they can find list of links to related topics in the Related section (Figure 1). This helps users if the first search result didn't show what they expected or the located resource is insufficient. According to Gormley and Tong [1], Elasticsearch [2] [3], the free search engine, generates these links on the website in real time from the growing and very impressive collection of 10 million StackOverflow contributions.
Artificial Brain
This isn't actual intelligence at work, because computers still find it difficult to understand the content of a document, meaning they can't find documents with related content. In fact, the algorithm used is based on simple nitpicking – it combines values for word frequency and derives a score from those values.
[...]
Buy this article as PDF
(incl. VAT)