Filesystem monitoring
Core Technology

Notification APIs in LInux.
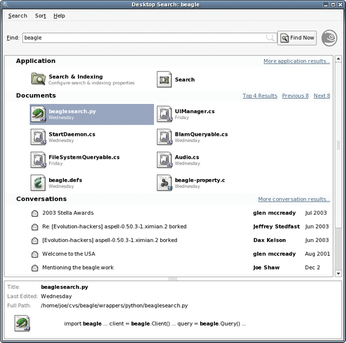
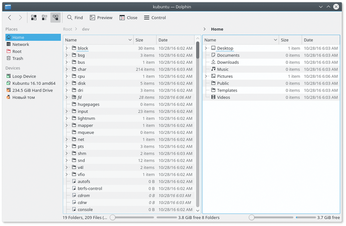
If you were using Linux back in 2006, you will remember the desktop search tool Beagle (Figure 1), which was notified when you changed your files so it could re-index them. Modern file managers also rely on notifications to update their displays when files are created, deleted, or renamed (Figure 2), unlike earlier file managers that counted on the user to refresh the display (Figure 3). Now, think of the ClamAV open source antivirus software. If you try to open a file containing malware, you expect an on-access scanner to ban it. In this case, notifications aren't enough; ClamAV needs to be an active part of the process, allowing or denying certain operations. Happily, Linux can handle both cases. The downside is, it does so with two separate APIs, and you can't just choose one over another.
[...]
Buy this article as PDF
(incl. VAT)