Easy steps for optimizing shell scripts
Speedier Scripts

Shell scripts are often written for simplicity rather than efficiency. A closer look at the processes can lead to easy optimization.
A shell script is essentially a sequence of commands and branches. Listing 1 shows a typical example. query.sh has all the basic components of a shell script. It contains keywords such as if, then, else, and fi; shell built-in commands such as echo and read; the square bracket; and last but not least, an external command (/bin/echo).
Listing 1
query.sh
#!/bin/bash echo "Own process ID: $$" echo -n "Are you an admin? " read answer if [ "$answer" = "Y" -o "$answer" = "y" ]; then echo "You are an admin." else /bin/echo "You are not an admin." fi
The calls to echo and /bin/echo behave differently, although they give you the same results. To see the difference, call the script twice while monitoring the shell with the command strace.
Listing 2 shows the first pass; Listing 3 uses Strace to display the corresponding output. At the start, the system creates a new shell process with a process identifier (PID) of 2489, which is responsible for processing the script. If you say y at the prompt, the output appears and the script is terminated (Listing 3, last line).
Listing 2
First Pass
# ./query.sh Own process ID: 2489 Are you an admin? y You are an admin.
Listing 3
Strace for echo
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,child_tidptr=0x7fa8fc515e50) = 2489
strace: Process 2489 attached
[pid 2489] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=2489, si_uid=0,si_status=0, si_utime=0, si_stime=0} ---
Now call the script a second time and say n when prompted (Listing 4). The branch now causes a call to the external command /bin/echo. Strace shows completely different output (Listing 5). In this case, a new shell process also started at the beginning (PID 2510). However, another process with a PID of 2511 is also created: This is the PID of /bin/echo.
Listing 4
No This Time
# ./query.sh Own process ID: 2510 Are you an admin? n You are not an admin
Listing 5
Strace with /bin/echo
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD,child_tidptr=0x7fa8fc515e50) = 2510
strace: Process 25attached
[pid 2510] clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7fbce6ffee50) = 2511
strace: Process 2511 attached
[pid 2511] +++ exited with 0 +++
[pid 2510] --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=2511,si_uid=0, si_status=0, si_utime=0, si_stime=0} ---
[pid 2510] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=2510, si_uid=0,si_status=0, si_utime=0, si_stime=0} ---
When a script calls external commands, the shell creates a new process, whereas the use of the commands built into the shell, such as echo, does not require an additional process. Figure 1 shows a schematic representation of the two examples. The graphic does not claim to be complete; it is only intended to show how the two call variants behave.
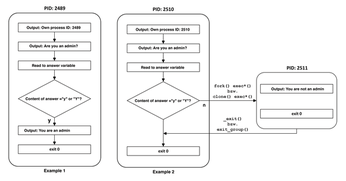
Subprocesses
The shell acts as an interactive interface between the user and the operating system. When you call a command, the shell stores the return values in environment variables.
Most shell commands are small programs of their own. Each program requires its own address space, registers, and other resources. Unix-like operating systems use a system call to fork() (on Linux this is clone()) to create a copy of the calling process. Within this copy, you then start the actual target program with the exec*() system call, which replaces the copied process.
The shell creates at least one additional subprocess when calling an external command, substituting commands, or using anonymous pipes. Using a function integrated into the shell, however, does not create a new subprocess.
Anonymous pipes are created by the | sign within a chain of commands. They are referred to as anonymous because they are not normally visible to the user – the system creates them and deletes them again after processing the data.
A process on Unix usually has three channels: STDIN (channel 0), STDOUT (channel 1), and STDERR (channel 2). The pipe normally reads the data from STDIN and outputs the data to STDOUT. Error messages are sent to STDERR.
If you are working with anonymous pipes, the first process redirects its output to STDIN of the process that follows the pipe symbol instead of STDOUT. In Listing 6, for example, the output from ls provides the input for the wc command. The output from wc is then ultimately sent to the standard output.
Listing 6
Pipe
$ ls -l | wc -l 282
You can only read from a pipe while a process is writing data to it. This explains why an anonymous pipe creates subprocesses: The wc command reads from the pipe as long as the ls command writes to it.
Anonymous pipes are also used for command substitution (Listing 7). In this case, the shell opens an additional channel that is used to read data – channel 3, if possible. The output of the concatenated command ends up in the filecount variable.
Listing 7
Command Substitution
# filecount=$(ls | wc -l) # echo $filecount 28
Script Tuning
Probably the most important rule for fast scripts is to avoid unnecessary subprocesses. Following are some examples to illustrate the effects of excessively long pipelines and command substitutions. The setup for this test includes 100,000 files in a folder, some of which contain the string 50 in one line.
In the first example (Listing 8), a loop evaluates each file. To do this, the script outputs each file with the cat command and redirects the output to the grep command. grep looks for lines containing the string 50 – so the string must be exactly two characters long, start with a 5, and end with a .
Listing 8
cat and grep
#!/bin/bash
# Example 1
for file in *; do
found=$(cat $file|grep "^50$"|wc -l)
if [ $found -ge 1 ]; then
echo $file
fi
done >number_files_1.out
The output from grep again provides the input for the wc command, which counts the lines found. The output from wc ends up in the found variable. If this variable assumes a value of 1, the script outputs the file name. Table 1 shows the results for this test and three other variants, each determined by the time command.
Table 1
Grep Timer
| Category | Input |
|||
|---|---|---|---|---|
| real |
3m52.327s |
2m36.079s |
1m2.970s |
0m0.372s |
| user |
3m11.611s |
1m40.114s |
0m46.838s |
0m0.083s |
| sys |
0m30.046s |
0m49.343s |
0m13.408s |
0m0.264s |
Listing 9 shows roughly the same approach, but this script does not store the output in a variable and does not determine the number of lines per file consisting of exactly the string 50. Because it requires fewer subprocesses, the modified script takes about 60 percent of the original execution time (see Table 1).
Listing 9
A Little Faster
#!/bin/bash
# Example 2
for file in *; do
cat $file|grep -q "^50$"
if [ $? -eq 0 ]; then
echo $file
fi
done >number_files_2.out
In the next step, the number of processes is reduced again, because the grep command itself opens the file and searches for the desired line. Then the script queries the return value and prints the file name if a matching line exists (Listing 10). The script now needs only about 30 percent of the original time to examine all files.
Listing 10
Even Faster
#!/bin/bash # Example 3 for file in *; do grep -q "^50$" $file if [ $? -eq 0 ]; then echo $file fi done >number_files_3.out
However, you can perform this task even faster. The grep command has a parameter that it uses to output the file name in case of a hit, instead of all lines of a file containing the string to be searched. A single call to the command is sufficient to check all files and output the names of the files (Listing 11).
Listing 11
Fastest
# time grep -l "^50$" * >number_files_4.out
The execution time is reduced to one six-hundredth of the original script from Listing 8. The enormous increase in speed is due to the fact that the shell now only creates one sub-process for the grep command. Figure 2 roughly sketches how the individual variants of the scripts differ.
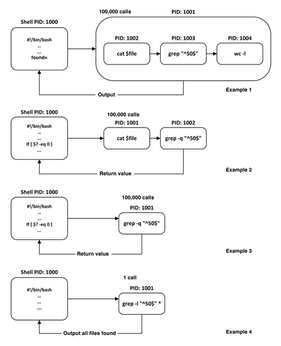
In the first example, running through 100,000 files requires four subprocesses each, for a total of 400,000. In the second example, two subprocesses per file are sufficient, for a total of 200,000. In the third example, this value is halved again, resulting in only 100,000 subprocesses. At the command line, however, a single additional process does the job.
Monitor the scripts at run time with Strace, and log the system calls that create new processes. A check using Grep for the clone keyword confirms the above values. To make sure that all variants return the same results, compare the output of the first example with all other output if necessary – there should be no difference.
Leveraging the Options
Many roads lead to Rome, but there are ways that will get you to your desired destination faster. In order to tweak the most speed out of scripts, you should give the commands you use as many tasks as possible.
For example: assume you want to print every third line from a file. The simplest way is to use tail to print all the lines starting at the desired position and redirect this output to the head command, which in turn only prints the first line from the lines it parses.
It is obvious that this solution is slow. It makes sense to move straight on to a more promising option: a loop with an incremented run index (Listing 12). If the index has a residual value of 0 when divided by 3 (modulo), the script outputs this line using the sed command. For a text file with 10,000 lines, the search and output took about 3.5 seconds (see Table 2).
Listing 12
sed at Work
#!/bin/bash typeset -i i=1 while [[ $i -le 10000 ]]; do if (($i % 3 == 0)); then # Runtime index modulo 3 sed -n "$i p" textfile fi ((i++)) done
Table 2
sed Timer
| Category | ||
|---|---|---|
| real |
0m3.474s |
0m0.026s |
| user |
0m2.591s |
0m0.006s |
| sys |
0m0.438s |
0m0.004s |
Listing 13
Awk Instead
#!/bin/bash
awk '{
if ((NR % 3 == 0))
# Index modulo 3
print $0
}' textfile
A far faster approach is to use Awk to read the file and determine every third line within the tool. The internal NR variable, which the software increments for each imported data record (usually one line), is fine for this purpose (Listing 13). Here the execution speed is many times higher, since the entire evaluation takes place within a single command.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia