Finding and retrieving Google Drive files with Go
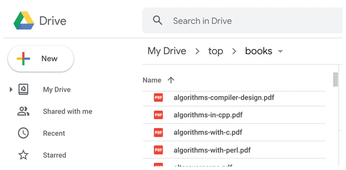
I have lots of PDFs of scanned books on my Google Drive and often download what I need from my digital bookshelf to my hard drive [1]. The browser interface on drive.google.com is very useful for this (Figure 1). However, Google Drive could be easier and faster to use when searching for books by listing the results and downloading matches immediately. The Go program presented in this issue does this at the command line, which goes down well with programmers who feel at home in the terminal window and are reluctant to ever leave it.
Building the source code from Listings 1 to 4 [2] and calling the generated binary that accepts a search string like algorithms-in-cpp is shown in Figure 2. On the user's Google Drive, the program finds the PDF for the book Algorithms in C++. It offers up the file for selection and downloads it after confirmation. While the PDF, which is around 150MB in size, is crossing the wire, the Go program displays a slow or fast progress bar, depending on the Internet connection, to give an impression on the number of bytes received in relation to the expected total number.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia