Working with the JSON data format
Element-by-Element Access
A tool like jq can dig out individual elements from the JSON data stream using expressions, but this approach is cumbersome for highly nested data structures; it is far easier to use a path specification. Tools like JMESPath [20] (pronounced "James Path") and JSONPath [21] are similar to XPath for XML. JMESPath is available in Python, PHP, JavaScript, or even Lua; JSONPath is available in JavaScript, PHP, and Java.
These tools enable more complex expressions. Table 5 shows you a selection. You read the expressions from left to right and name nodes or attributes in the order in which you want to work your way along the data structure. Two levels of nodes or attributes are separated by a period. Sets and patterns are specified in square brackets, for example, book[*] for all nodes of the book list. The specification book[?author == `Ken Follett`] takes all nodes from the dataset for which the attribute author has the value Ken Follett.
Table 5
Expressions in JMESPath
| Expression | Meaning |
|---|---|
| book[*].title |
All book titles |
| book[?author == `Ken Follett`].title |
All book titles by author Ken Follett |
| book[?publication > `1990`] |
All books published after 1990 |
Please note the correct quotes when formulating the expressions. You need to quote values for comparison in the call in backticks (`), regardless of whether they are strings or numeric values.
Listing 13 shows the three expressions from Table 5 in action in a Python script. We used the JSON implementation of JMESPath here. Although the Json library is a fixed part of Python, JMESPath is one of the extras that you can install before using it, either via Pip or the package manager that comes with your Linux distribution. The corresponding package for Debian GNU/Linux and Ubuntu goes by the name of python3-jmespath.
Listing 13
find-json-path.py
01 import jmespath
02 import json
03
04 expression1 = jmespath.compile('book[*].title')
05 expression2 = jmespath.compile('book[?author == `Ken Follett`].title')
06 expression3 = jmespath.compile('book[?publication > `1990`]')
07
08 with open("bookinventory.json") as jsonFile:
09 jsonData = json.load(jsonFile)
10
11 # book titles
12 print("Book title:")
13 bookTitles = expression1.search(jsonData)
14 for title in bookTitles:
15 print(title)
16
17 print(" ")
18
19 # all the books by Ken Follett
20 print("All books by Ken Follett:")
21 bookTitles = expression2.search(jsonData)
22 for title in bookTitles:
23 print(title)
24
25 print(" ")
26
27 # all books published later than 1990
28 print("All books published later than 1990:")
29 books = expression3.search(jsonData)
30 for item in books:
31 author = item["author"]
32 title = item["title"]
33 publication = item["publication"]
34 print("Author : %s" % author)
35 print("Title : %s" % title)
36 print("Published: %i" % publication)
37 print(" ")
After first loading the two Python libraries, json and jmespath, in the script (lines 1 and 2), three expressions or search patterns are defined as objects with the names expression1, expression2, and expression3. If you are familiar with the Python regular expression library re, you will already know the procedure.
Lines 8 and 9 read the book inventory as a JSON file and load() the contents of the file as a dictionary into the jsonData variable. Searches over the book inventory rely on the search() method from the search pattern object. For example, the call to expression2.search(jsonData) searches out all book titles that belong to the author Ken Follett.
search() returns a list of search hits that you can output one by one in a for loop. Figure 8 shows the output of the search matches for all three previously defined search paths.
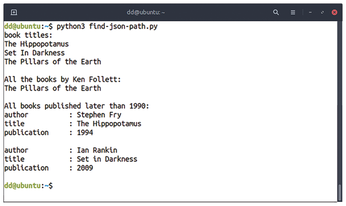
JSON Libraries
If you prefer some other programming language instead of Python, you can still connect to JSON. Table 6 shows a selection of libraries and modules. If you have different implementations available for a programming language, it is difficult to make a recommendation without knowing the volume and structure of the JSON data you wish to process. After a benchmark test, you will be smarter [22] about what best suits your case.
Table 6
Selection of JSON Libraries
| Language | Libraries (Selection) |
|---|---|
| Go |
encoding/json |
| LISP |
CL-JSON |
| Lua |
json.lua |
| NodeJS |
Express |
| Perl |
JSON::Parse, JSON::PP, JSON::XS |
| PHP |
JSON |
| Python |
simplejson, hyperjson, json, jsonschema, orjson, RapidJSON, UltraJSON, pandas |
| Ruby |
JSON |
| Tcl |
json |
Listing 14 shows how to access JSON objects in the Go programming language. After importing the two modules encoding/json and fmt, you create a Book data structure that includes three variables: Author, Title, and Publication. You access this data structure in the main() function by declaring a book variable with this type in it.
Listing 14
extract-json.go
package main
import (
"encoding/json"
"fmt"
)
type Book struct {
Author string
Title string
Publication string
}
func main() {
bookJson := `{"author": "Stephen Fry", "title": "The Hippopotamus", "publication": "1994"}`
var book Book
json.Unmarshal([]byte(bookJson), &book)
fmt.Println("Author: ", book.Author)
fmt.Println("Title: ", book.Title)
fmt.Println("Publication: ", book.Publication)
}
The bookJson variable acquires the record for a book. Using the Unmarshal() method from the json module, you unpack the record byte by byte and assign the contents to the components from book. Then, using the Println() method, you output the contents of the components. For more information on processing, see Soham Kamani's blog [23], which is definitely a worthwhile read.
Now save Listing 14 to the extract-json.go file and run the code. You'll see something like the output in Listing 15.
Listing 15
Output
$ go run extract-json.go Author: Stephen Fry Title: The Hippopotamus Publication: 1994
Outlook
Using JSON is a good choice if the data conforms to the supported formats, the strings are not arbitrarily long, and you only need to implement the data exchange, while the documentation of the data is managed elsewhere. Another strength of JSON is that many languages can process it.
With large volumes of data, however, the file size can have a detrimental effect on the processing speed. In those cases, a different format such as Google's Protobuf [24] could offer an alternative. For more information on serialization formats and the practical handling of JSON, see the examples in the Jupyter tutorial [25].
Thank you
The authors would like to thank Gerold Rupprecht for his criticism and suggestions during the preparation of the article.
Infos
- JSON: https://www.json.org/
- Jupyter Notebook: https://jupyter.org/try
- GeoJSON: https://geojson.org
- RFC 8259: https://tools.ietf.org/html/rfc8259
- aeson-pretty: https://github.com/informatikr/aeson-pretty
- jc: https://github.com/kellyjonbrazil/jc
- jid: https://github.com/simeji/jid
- jo: https://github.com/jpmens/jo
- jq: https://github.com/stedolan/jq
- Jshon: http://kmkeen.com/jshon
- JSONLint: https://jsonlint.com
- jq cheat sheet: https://lzone.de/cheat-sheet/jq
- jc demo website: https://jc-web-demo.herokuapp.com
- JSON Viewer: https://jsonviewer.arianv.com
- JSON validators: https://json-schema.org/implementations.html#validators
- validate-json: https://github.com/justinrainbow/json-schema
- jsonschema: https://github.com/Julian/jsonschema
- Validation of JSON data: http://json-schema.org/draft/2019-09/json-schema-validation.html
- "List of JSON tools for command line": https://ilya-sher.org/2018/04/10/list-of-json-tools-for-command-line/
- JMESPath: https://jmespath.org
- JSONPath: https://code.google.com/archive/p/jsonpath/
- "Choosing a faster JSON library for Python": https://pythonspeed.com/articles/faster-json-library/
- "How to Parse JSON in Golang": https://www.sohamkamani.com/blog/2017/10/18/parsing-json-in-golang/
- Protobuf: https://developers.google.com/protocol-buffers
- Serialization formats/JSON (Jupyter Tutorial): https://jupyter-tutorial.readthedocs.io/en/latest/data-processing/serialisation-formats/json.html
« Previous 1 2 3 4
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia