A bag o' tricks from the Perlmeister
Undercover Information

If you have been programming for decades, you've likely gathered a personal bag of tricks and best practices over the years – much like this treasure trove from the Perlmeister.
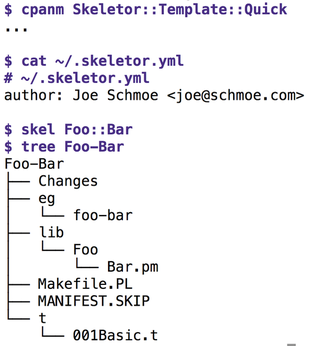
For each new Perl project – and I launch several every week – it is necessary to first prime the working environment. After all, you don't want a pile of spaghetti scripts lying around that nobody can maintain later. A number of template generators are available on CPAN. My attention was recently drawn to App::Skeletor, which uses template modules to adapt to local conditions. Without further ado, I wrote Skeletor::Template::Quick to adapt the original to my needs and uploaded the results to CPAN.
If you store the author info, as shown in Figure 1, in the ~/.skeletor.yml file in your home directory and, after installing the Template module from CPAN, run the skel Foo::Bar command, you can look forward to instantly having a handful of predefined files for a new CPAN distribution dumped into a new directory named Foo-Bar. Other recommended tools for this scaffolding work would be the built-in Perl tool h2xs or the CPAN Module::Starter module.
[...]
Buy this article as PDF
(incl. VAT)