Car NOT Goat
Programming Snapshot – Neural Networks

© Lead Image © Frantisek Hojdysz, 123RF.com
The well-known Monty Hall game show problem can be a rewarding maiden voyage for prospective statisticians. But is it possible to teach a neural network to choose between goats and cars with a few practice sessions?
Here's the problem: In a game show, a candidate has to choose from three closed doors; waiting behind these doors is a car, which is the main prize, a goat, and yet another goat (Figure 1). The candidate first picks a door, and then the presenter opens another, behind which there is a bleating goat. How is the candidate most likely to win the grand prize: Sticking with their choice or switching to the remaining closed door?
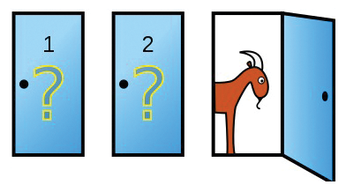
As has been shown [1] [2], the candidate is better off switching, because then they double their chances of winning. But how does a neural network learn the optimal game strategy while being rewarded for wins and punished for losses?
[...]
Buy this article as PDF
(incl. VAT)