Car NOT Goat
Programming Snapshot – Neural Networks

© Lead Image © Frantisek Hojdysz, 123RF.com
The well-known Monty Hall game show problem can be a rewarding maiden voyage for prospective statisticians. But is it possible to teach a neural network to choose between goats and cars with a few practice sessions?
Here's the problem: In a game show, a candidate has to choose from three closed doors; waiting behind these doors is a car, which is the main prize, a goat, and yet another goat (Figure 1). The candidate first picks a door, and then the presenter opens another, behind which there is a bleating goat. How is the candidate most likely to win the grand prize: Sticking with their choice or switching to the remaining closed door?
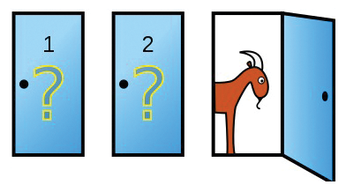
As has been shown [1] [2], the candidate is better off switching, because then they double their chances of winning. But how does a neural network learn the optimal game strategy while being rewarded for wins and punished for losses?
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Substantial Update to IPFire Now Available
The lastest version of IPFire features a fundamental change to how the system handles DNS.
-
Gnome Working on Test Center App to Make Testing Easier
It's now possible to test experimental features on the Gnome desktop without worrying that you'll break things.
-
New Vulnerability Discovered in Linux Kernel
Hiding out for nearly 15 years, the Ghostlock vulnerability allows a standard logged-in user to gain root privileges.
-
New Linux Flaw Lets Attackers Escape VMs
A 16-year-old vulnerability allows an attacker to escape a virtual machine, gain access to the host, and execute malicious code.
-
Hannah Montana Linux Is Back!
Developer Noah Cagle decided the world needed the once obscure but beloved Linux distribution and gave it a decidedly pink refresh.
-
System76 Refreshes the Lemur Laptop
If you're looking for a laptop with tons of power and battery, look no further than the latest iteration of the System76 Lemur Pro.
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
-
Linux Gamers May Soon See Less Mouse Lag in KDE Plasma
Gamers using KDE’s Plasma desktop have been suffering from a slight input delay in mouse movement that could lead to getting fragged.
-
Three Lines of Code Improve Linux Storage Performance
A developer changed three lines of code, giving Linux storage performance a 5% bump.