Scraping highly dynamic websites
Full-Text Search
How can the newly launched browser drone simulate user interactions such as mouse clicks or keyboard strokes to follow more complicated web flows? The chromedp library offers functions to select certain form fields or buttons from the displayed web page's DOM via an XPath query and communicates with them via SendKeys(), Submit(), or Click().
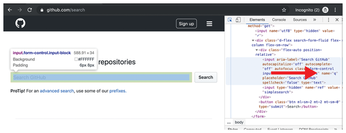
For example, to fire off a full-text search of all repositories on GitHub, you first need to discover the name of the search field there. A quick look in the Chrome browser's developer view (via the Inspect Elements menu) reveals that the search field goes by the name attribute q (Figure 2). Line 15 from Listing 3 defines the associated XPath query //input[@name="q"] in the sel variable. After accessing the GitHub page, the WaitVisible() task in line 19 waits until the search field arrives via the Internet's series of tubes.
Listing 3
github.go
01 package main
02
03 import (
04 "context"
05 "fmt"
06 "github.com/chromedp/cdproto/dom"
07 cdp "github.com/chromedp/chromedp"
08 )
09
10 func main() {
11 ctx, cancel :=
12 cdp.NewContext(context.Background())
13 defer cancel()
14
15 sel := `//input[@name="q"]`
16 tasks := cdp.Tasks{
17 cdp.Navigate(
18 "https://github.com/search"),
19 cdp.WaitVisible(sel),
20 cdp.SendKeys(sel, "waaah\n"),
21 cdp.WaitReady("body", cdp.ByQuery),
22 cdp.ActionFunc(
23 func(ctx context.Context) error {
24 node, err := dom.GetDocument().Do(ctx)
25 if err != nil {
26 panic(err)
27 }
28 res, err := dom.GetOuterHTML().
29 WithNodeID(node.NodeID).Do(ctx)
30 if err != nil {
31 panic(err)
32 }
33 fmt.Printf("html=%s\n", res)
34 return nil
35 }),
36 }
37 err := cdp.Run(ctx, tasks)
38 if err != nil {
39 panic(err)
40 }
41 }
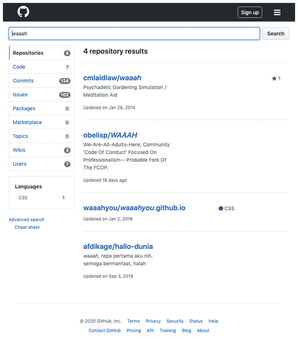
The SendKeys() function in line 20 then sends the search string (waaah) to the input field and terminates it with a newline character. This is enough to prompt the GitHub UI to initiate the search without having to press a Submit button. Line 21 then waits with WaitReady("body", cdp.ByQuery) until the result is available, before initiating the output of the returned raw HTML with a user-defined ActionFunc().
With the content displayed in Figure 3, it then uses dom.GetDocument() to retrieve the root node of the HTML document and dom.GetOuterHTML() to get the raw HTML code on the page. For test purposes, the Printf() function outputs the displayed page's source code; a scraper application could extract interesting content from this and process it further.
Not Entirely Welcome
Chromedp supports all Chrome and Edge browsers, but not Firefox, which is based on a different technology. The chromedp project on GitHub is trying to keep up with new Chrome versions and changes to the DevTools protocol: Sometimes, things don't work as expected, and workarounds have to be found.
There are open issues on the GitHub projects, and the developers are addressing problems with new versions of the library. Besides Google's official documentation [2], there are some tutorials online, but not a thorough and practical publication on the topic. At least, I found a book [5] that contains a huge amount of useless filler material, but also covers various topics in the field of web scraping and briefly discusses Selenium and Chrome DevTools.
Popular websites like Facebook, Twitter, or Google also seem to be interested in making scraping with tools like chromedp as hard as possible. For example, Gmail uses dynamically generated random names for the input fields on the login page. In addition, ongoing changes to the page layout often require a scraper adjustment, so that the whole undertaking remains an arms race between the content provider and the scraper developers. The industry giants want to bind their users to the official pages in order to bombard them with advertising, because, let's face it, somebody has to pay the server bill at the end of the month.
Infos
- "Programming Snapshot – Colly" by Mike Schilli, Linux Magazine, issue 223, June 2019, pp. 54-57
- Chrome DevTools: https://developers.google.com/web/tools/chrome-devtools/
- chromedp: https://github.com/chromedp/chromedp
- Listings for this article: ftp://ftp.linux-magazine.com/pub/listings/linux-magazine.com/234/
- Smith, Vincent. Go Web Scraping Quick Start Guide, Packt Publishing, 2019, https://learning.oreilly.com/library/view/go-web-scraping/9781789615708/cover.xhtml
The Author

Mike Schilli works as a software engineer in the San Francisco Bay area, California. Each month in his column, which has been running since 1997, he researches practical applications of various programming languages. If you email him at mailto:mschilli@perlmeister.com he will gladly answer any questions.
« Previous 1 2
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia