Getting started with the ELK Stack monitoring solution
Elk Hunting

© Photo by David Santoyo on Unsplash
ELK Stack is a powerful monitoring system known for efficient log management and versatile visualization. This hands-on workshop will help you take your first steps with setting up your own ELK Stack monitoring solution.
Today's networks require a monitoring solution with industrial-strength log management and analytics. One option that has gained popularity in recent years is ELK stack [1]. The free and open source ELK Stack collection is maintained by a company called Elastic. (According to the website, the company has recently changed the name of the project to Elastic Stack, but the previous name is still in common usage.) ELK Stack is not a single tool but a collection of tools (Figure 1). The ELK acronym highlights the importance of the collection's three most important utilities. At the heart of the stack, Elasticsearch collects and maintains data, providing an engine, based on Apache Lucene, for searching through it. Logstash serves as the log processing pipeline, collecting data from a multitude of sources, transforming it, then sending it to a chosen "stash." (Keep in mind that, despite its name, Logstash itself does not preserve any data.) Kibana provides a user-friendly interface for querying and visualizing the data.
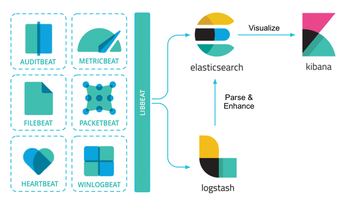
A bundle of tiny apps called beats specialize in collecting data and feeding it to Logstash or Elasticsearch. The beats include:
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia