Advanced Bash techniques for automation, optimization, and security
Subshells and Process Substitution
Subshells in Bash allow you to run commands in a separate execution environment, making them ideal for isolating variables or capturing command outputs. A common use case is encapsulating logic to prevent side effects (Listing 3).
Listing 3
Subshell
( cd /tmp || exit echo "Current Directory in Subshell: $(pwd)" ) echo "Current Directory in Parent Shell: $(pwd)"
Here, changes made in the subshell, such as switching directories, do not affect the parent shell (Figure 2). This isolation is particularly useful in complex scripts where you want to maintain a clean environment.

Process substitution is another powerful Bash feature that allows you to treat the output of a command as if it were a file. This capability enables seamless integration of commands that expect file inputs:
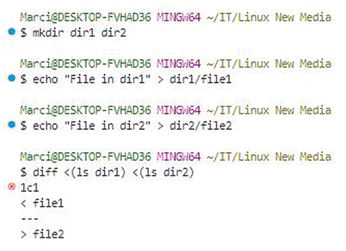
diff <(ls /dir1) <(ls /dir2)
The ls commands generate directory listings, which diff compares as if they were regular files (Figure 3). Process substitution enhances script efficiency by avoiding the need for intermediate temporary files.
For scenarios involving data pipelines, process substitution can be combined with tee to simultaneously capture and process output:
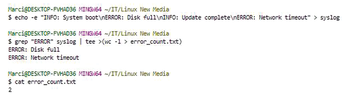
grep "ERROR" /var/log/syslog | tee >(wc -l > error_count.txt)
This command filters error messages from a logfile, then tee allows you to count and log the errors simultaneously, demonstrating both flexibility and efficiency (Figure 4).
Scripting for Automation
Automation is at the heart of managing complex Linux environments, where tasks like parsing logs, updating systems, and handling backups must be executed reliably and efficiently. Shell scripting provides the flexibility to streamline these operations, ensuring consistency, scalability, and security. In this part, I will explore practical examples of dynamic logfile parsing, automated system updates, and efficient backup management, with a focus on real-world applications that IT professionals encounter in their daily workflows.
Logfile Parsing and Data Extraction
Logs are invaluable for monitoring system health, diagnosing issues, and maintaining compliance. However, manually analyzing logfiles in production environments is both impractical and error-prone. Shell scripts can dynamically parse logs to extract relevant data, highlight patterns, and even trigger alerts for specific conditions.
Consider the example of extracting error messages from a system log (/var/log/syslog) and generating a summary report. A script can achieve this dynamically (Listing 4).
Listing 4
Log Summary
#!/bin/bash
log_file="/var/log/syslog"
output_file="/var/log/error_summary.log"
# Check if log file exists
if [[ ! -f $log_file ]]; then
echo "Error: Log file $log_file does not exist."
exit 1
fi
# Extract error entries and count occurrences
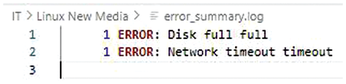
grep -i "error" "$log_file" | awk '{print $1, $2, $3, $NF}' | sort | uniq -c > "$output_file"
echo "Error summary generated in $output_file"
This script checks for the presence of the logfile, extracts lines containing "error," processes them with awk to focus on specific fields (like timestamps and error codes), and generates a summarized output (Figure 5). The use of sort and uniq ensures that recurring errors are grouped and counted. This approach can be extended to handle different log formats or integrate with tools like jq for JSON-based logs.
In a cloud environment, similar scripts can be used to parse logs from multiple instances via SSH or integrated with centralized logging systems like Elastic Stack.
Buy this article as PDF
(incl. VAT)