Bringing Up Clouds
Defining Settings
Now, the last missing bit is how you define settings that are specific to the instance, and that's where things start to get really interesting.
Cloud-init implements a data source concept that provides an abstraction for the data, which comes from the cloud content management system (CMS), such as OpenStack. Hostname, locale, or SSH keys are all valid examples. Moreover, a data source provides so-called user data and vendor data. For cloud-init to consume user data, it must come as a MIME multipart archive, which is the same format you use when sending email messages with attachments. Each part (or file) has an associated Content-type header and also begins with a signature: #something; cloud-init uses this information to decide how to handle the particular part.
User data is typically no more than 16KB. To overcome this limitation, the #include file can list additional URLs, one per line. They are retrieved and treated as if their contents were a part of the original user data. To make things even more compact, you can use Gzip compression. The #cloud-config file is in essence an /etc/cloud/cloud.cfg snippet embedded in user data. A few other types are supported out of the box, such as raw shell scripts, and it's possible to define your own content types and their respective handlers. See the Formats section on the cloud-init documentation page [3] for details.
Cloud-init comes with a variety of data source modules and enables most of them by default. You can redefine this via the datasource key in /etc/cloud/cloud.cfg. This makes sense, because you typically know which data sources are available in your cloud. Some data sources need network access, and some don't. When started, cloud-init probes enabled data sources one by one, and the first one that replies wins.
Perhaps the simplest data source is the OpenStack configuration drive, ConfigDrive. It's a tiny disk image (ISO 9660, or VFAT in earlier versions), and it is employed sometimes to provide networking settings. Cloud-init can then apply these settings and use a full-fledged data source, such as EC2 metadata, to do the rest of the configuration. In theory, ConfigDrive can provide you with all of the metadata, but a dedicated metadata service would work better.
What's metadata, you ask? It's data that describes the running VM instance. Typically, it's encoded in JSON and comes from an HTTP service listening on a link-local address (e.g., 169.254.169.254). In reality, this server is just a proxy that forwards requests to the CMS. The exact API is, of course, cloud-specific, but perhaps the two most popular are EC2 metadata [9] and OpenStack metadata, which is an extension to EC2. Listing 2 shows the anatomy of the latter.
Listing 2
Sample OpenStack Metadata (Abbreviated)
The name assigned to this VM is hostname. The set_hostname module uses this bit of data to apply the setting in a distro-specific way. The ssh module installs public_keys, the SSH keys for the default user, and random_seed is a 512-byte base64-encoded blob of random data that usually comes from the host's /dev/urandom and serves as an external entropy supply to the VM. All VM instances start off of the same image and perform roughly the same initialization steps, so their kernels end up with similar entropy pools. This could be a security breach, as random numbers are often seen in cryptography, and they should be, well, random, not the same as on your neighbor's VM. Moreover, because VMs typically do not have so much hardware from which to collect the noise, their pools are easily exhausted, making tasks such as SSH key generation hang. The seed_random module is here to plug into these holes.
Command of the Month: ec2-metadata
While it's trivial to query cloud metadata with curl, it is certainly not the most convenient way. You get raw unformatted JSON that you feed to Python to make it barely readable; then, you look up the reference documentation to learn the meaning of all of the fields.
If you are on AWS or another cloud that serves EC2-compatible metadata, there is a better way. ec2-metadata is a command-line tool that you can use to query metadata in scripts or interactive sessions. It supports Linux and runs on top of curl, so make sure you have the latter installed.
To begin, download ec2-metadata from Amazon S3:
curl -o ec2-metadata http://s3.amazonaws.com/ec2metadata/ec2-metadata
Next, make it executable (it's a Bash script), and type
./ec2-metadata --help
to see the options available. Note this won't work if EC2 metadata is unavailable, even if displaying the help page doesn't require metadata access. ec2-metadata dumps all information by default, but you can narrow down the output using one of the command-line switches. For example,
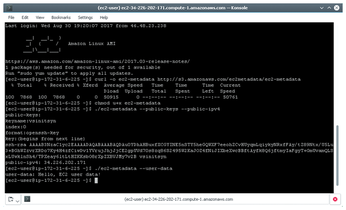
./ec2-metadata --public-keys --public-ipv4 public-keys: ... public-ipv4: 34.226.202.171
lists public keys and the IPv4 address assigned to the instance (Figure 4).
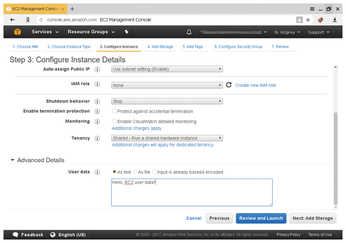
To retrieve user data, enter
./ec2-metadata --user-data user-data: Hello, EC2 user data!
(see also Figure 5).
Note that it doesn't have to be anything related to the cloud-init multipart data format. Although the instance metadata is not what you are interested in most of the time, tools such as ec2-metadata could aid troubleshooting in cases when cloud-init fails to initialize the instance properly – for whatever reason.
Infos
- Cloud-init homepage: https://cloud-init.io/
init(1)man page: http://man7.org/linux/man-pages/man1/init.1.html- cloud-init documentation: http://cloudinit.readthedocs.io/
- The Salt Open Source Software Project: https://saltstack.com/community/
systemd.generator(7)man page: https://www.freedesktop.org/software/systemd/man/systemd.generator.html- YAML cheat sheet: https://learnxinyminutes.com/docs/yaml/
- Generic OpenStack images: https://docs.openstack.org/image-guide/obtain-images.html
ssh-import-idhomepage: https://launchpad.net/ssh-import-id- Amazon EC2 instance metadata and user data: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-metadata.html
« Previous 1 2
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Canonical Releases Ubuntu 24.04
After a brief pause because of the XZ vulnerability, Ubuntu 24.04 is now available for install.
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.