Calculating Probability
Perl – Think Again

To tackle mathematical problems with conditional probabilities, math buffs rely on Bayes' formula or discrete distributions, generated by short Perl scripts.
Features
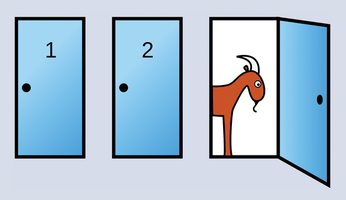
The Monty Hall problem is loved by statisticians around the world [1]. You might be familiar with this puzzle, in which a game show host offers a contestant a choice of three doors – behind one door is a prize, but the other two doors only reveal goats. After the contestant chooses a door, the TV host opens a different door, revealing a goat, and asks the candidate to reconsider (Figure 1). Who would have thought that probabilities in a static television studio could change so dramatically just because the host opens a door without a prize?
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Yet Another Linux Kernel Vulnerability Discovered
Affecting millions of systems, a kernel flaw discovered by Qualys could allow users to gain root privileges.
-
Ubuntu 26.10 to Include Ubuntu Certified Hardware Check
If you've ever wondered if your laptop or PC is officially certified to run Ubuntu, that curiosity will soon be met.
-
Substantial Update to IPFire Now Available
The lastest version of IPFire features a fundamental change to how the system handles DNS.
-
Gnome Working on Test Center App to Make Testing Easier
It's now possible to test experimental features on the Gnome desktop without worrying that you'll break things.
-
New Vulnerability Discovered in Linux Kernel
Hiding out for nearly 15 years, the Ghostlock vulnerability allows a standard logged-in user to gain root privileges.
-
New Linux Flaw Lets Attackers Escape VMs
A 16-year-old vulnerability allows an attacker to escape a virtual machine, gain access to the host, and execute malicious code.
-
Hannah Montana Linux Is Back!
Developer Noah Cagle decided the world needed the once obscure but beloved Linux distribution and gave it a decidedly pink refresh.
-
System76 Refreshes the Lemur Laptop
If you're looking for a laptop with tons of power and battery, look no further than the latest iteration of the System76 Lemur Pro.
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.