Calculating Probability
Perl – Think Again

To tackle mathematical problems with conditional probabilities, math buffs rely on Bayes' formula or discrete distributions, generated by short Perl scripts.
Features
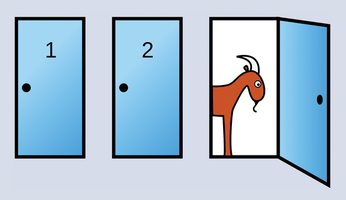
The Monty Hall problem is loved by statisticians around the world [1]. You might be familiar with this puzzle, in which a game show host offers a contestant a choice of three doors – behind one door is a prize, but the other two doors only reveal goats. After the contestant chooses a door, the TV host opens a different door, revealing a goat, and asks the candidate to reconsider (Figure 1). Who would have thought that probabilities in a static television studio could change so dramatically just because the host opens a door without a prize?
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Mozilla Plans to AI-ify Firefox
With a new CEO in control, Mozilla is doubling down on a strategy of trust, all the while leaning into AI.
-
Gnome Says No to AI-Generated Extensions
If you're a developer wanting to create a new Gnome extension, you'd best set aside that AI code generator, because the extension team will have none of that.
-
Parrot OS Switches to KDE Plasma Desktop
Yet another distro is making the move to the KDE Plasma desktop.
-
TUXEDO Announces Gemini 17
TUXEDO Computers has released the fourth generation of its Gemini laptop with plenty of updates.
-
Two New Distros Adopt Enlightenment
MX Moksha and AV Linux 25 join ranks with Bodhi Linux and embrace the Enlightenment desktop.
-
Solus Linux 4.8 Removes Python 2
Solus Linux 4.8 has been released with the latest Linux kernel, updated desktops, and a key removal.
-
Zorin OS 18 Hits over a Million Downloads
If you doubt Linux isn't gaining popularity, you only have to look at Zorin OS's download numbers.
-
TUXEDO Computers Scraps Snapdragon X1E-Based Laptop
Due to issues with a Snapdragon CPU, TUXEDO Computers has cancelled its plans to release a laptop based on this elite hardware.
-
Debian Unleashes Debian Libre Live
Debian Libre Live keeps your machine free of proprietary software.
-
Valve Announces Pending Release of Steam Machine
Shout it to the heavens: Steam Machine, powered by Linux, is set to arrive in 2026.