Of lakes and sparks – How Hadoop 2 got it right
Misconceptions

Hadoop version 2 has transitioned from an application to a Big Data platform. Reports of its demise are premature at best.
In a recent story on the PCWorld website titled "Hadoop successor sparks a data analysis evolution," the author predicts that Apache Spark will supplant Hadoop in 2015 for Big Data processing [1]. The article is so full of mis- (or dis-)information that it really is a disservice to the industry. To provide an accurate picture of Spark and Hadoop, several topics need to be explored in detail.
First, like any article on "Big Data," is it important to define exactly what you are talking about. The term "Big Data" is a marketing buzz-phase that has as much meaning as things like "Tall Mountain" or "Fast Car." Second, the concept of the data lake (less of a buzz-phrase and more descriptive than Big Data) needs to be defined. Third, Hadoop version 2 is more than a MapReduce engine. Indeed, if there is anything to take away from this article it is the message in Figure 1. And, finally, how Apache Spark neatly fits into the Hadoop ecosystem will be explained.
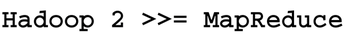
[...]
Buy this article as PDF
(incl. VAT)